
Docker Kafka Container


Are you looking to set up a Kafka ecosystem containers using Docker on your MacOS machine? Look no further! In this article, we will explore the process of setting up a Kafka cluster, creating topics, connectors, and streams using Confluent's tools, including Schema Registry and ksqlDB. We will also cover how to use Docker to run these components in a local environment.
Setup
We will be deploying Kafka based on Kraft rather than Zookeeper.
Components we will deploy are-
- Kafka Broker
- Confluent Schema Registry
- Confluent REST Proxy
- Kafka Connect
- ksqlDB
- Kafka-UI
Create an Environment File
The first step is to create an environment file that will store our Cluster ID.
.env
CLUSTER_ID=AsK12ABCDExyABCDEFG99xCreate a Docker Compose File
Next, we'll create a Docker compose file that defines our Kafka containers.
kafka-docker-compose.yml
version: '3.9'
services:
broker:
# Apple M1 Chip
# platform: linux/amd64
image: confluentinc/cp-kafka:7.4.0
container_name: broker
hostname: broker
restart: always
env_file:
- .env
environment:
KAFKA_NODE_ID: 1
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: broker
KAFKA_JMX_OPTS: -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=broker -Dcom.sun.management.jmxremote.rmi.port=9101
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@broker:29093
KAFKA_LISTENERS: PLAINTEXT://broker:29092,CONTROLLER://broker:29093,PLAINTEXT_HOST://0.0.0.0:9092
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
# KAFKA_LOG_DIRS: /tmp/kraft-combined-logs
KAFKA_LOG_DIRS: /var/lib/kafka/data
# Replace CLUSTER_ID with a unique base64 UUID using "bin/kafka-storage.sh random-uuid"
# See https://docs.confluent.io/kafka/operations-tools/kafka-tools.html#kafka-storage-sh
CLUSTER_ID: $CLUSTER_ID
ports:
- 9092:9092
- 9101:9101
volumes:
- broker_logdir:/var/lib/kafka/data
networks:
- kafka-network
schema-registry:
# Apple M1 Chip
# platform: linux/amd64
image: confluentinc/cp-schema-registry:7.4.0
container_name: schema-registry
hostname: schema-registry
restart: always
env_file:
- .env
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: broker:29092
SCHEMA_REGISTRY_LISTENERS: http://0.0.0.0:8081
SCHEMA_REGISTRY_KAFKASTORE_TOPIC: __schemas
ports:
- 8081:8081
networks:
- kafka-network
depends_on:
- broker
rest-proxy:
# Apple M1 Chip
# platform: linux/amd64
image: confluentinc/cp-kafka-rest:7.4.0
container_name: rest-proxy
hostname: rest-proxy
restart: always
env_file:
- .env
environment:
KAFKA_REST_HOST_NAME: rest-proxy
KAFKA_REST_BOOTSTRAP_SERVERS: broker:29092
KAFKA_REST_LISTENERS: http://0.0.0.0:8082
KAFKA_REST_SCHEMA_REGISTRY_URL: http://schema-registry:8081
ports:
- 8082:8082
networks:
- kafka-network
depends_on:
- broker
- schema-registry
kafka-connect:
# Apple M1 Chip
# platform: linux/amd64
image: confluentinc/cp-kafka-connect:7.4.0
container_name: kafka-connect
hostname: kafka-connect
restart: always
env_file:
- .env
environment:
CONNECT_BOOTSTRAP_SERVERS: broker:29092
CONNECT_REST_ADVERTISED_HOST_NAME: kafka-connect
CONNECT_GROUP_ID: kafka-connect
CONNECT_CONFIG_STORAGE_TOPIC: __connect-config
CONNECT_OFFSET_STORAGE_TOPIC: __connect-offsets
CONNECT_STATUS_STORAGE_TOPIC: __connect-status
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.storage.StringConverter
CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter
CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: http://schema-registry:8081
# CLASSPATH required due to CC-2422
CLASSPATH: /usr/share/java/monitoring-interceptors/monitoring-interceptors-7.4.0.jar
CONNECT_PRODUCER_INTERCEPTOR_CLASSES: io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor
CONNECT_CONSUMER_INTERCEPTOR_CLASSES: io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor
CONNECT_PLUGIN_PATH: /usr/share/java,/usr/share/confluent-hub-components,/data
CONNECT_LOG4J_LOGGERS: org.apache.zookeeper=ERROR,org.I0Itec.zkclient=ERROR,org.reflections=ERROR
command:
- bash
- -c
- |
confluent-hub install --no-prompt confluentinc/kafka-connect-datagen:0.6.0
confluent-hub install --no-prompt confluentinc/kafka-connect-s3:10.5.0
confluent-hub install --no-prompt confluentinc/connect-transforms:1.4.3
/etc/confluent/docker/run &
sleep infinity
ports:
- 8083:8083
volumes:
- $PWD/data:/data
networks:
- kafka-network
depends_on:
- broker
- schema-registry
ksqldb-server:
# Apple M1 Chip
# platform: linux/amd64
image: confluentinc/cp-ksqldb-server:7.4.0
container_name: ksqldb-server
hostname: ksqldb-server
restart: always
env_file:
- .env
environment:
KSQL_CONFIG_DIR: /etc/ksql
KSQL_BOOTSTRAP_SERVERS: broker:29092
KSQL_HOST_NAME: ksqldb-server
KSQL_LISTENERS: http://0.0.0.0:8088
KSQL_CACHE_MAX_BYTES_BUFFERING: 0
KSQL_KSQL_SCHEMA_REGISTRY_URL: http://schema-registry:8081
KSQL_PRODUCER_INTERCEPTOR_CLASSES: io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor
KSQL_CONSUMER_INTERCEPTOR_CLASSES: io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor
KSQL_KSQL_CONNECT_URL: http://kafka-connect:8083
KSQL_KSQL_LOGGING_PROCESSING_TOPIC_REPLICATION_FACTOR: 1
KSQL_KSQL_LOGGING_PROCESSING_TOPIC_AUTO_CREATE: true
KSQL_KSQL_LOGGING_PROCESSING_STREAM_AUTO_CREATE: true
ports:
- 8088:8088
networks:
- kafka-network
depends_on:
- broker
- schema-registry
- kafka-connect
kafka-ui:
# Apple M1 Chip
# platform: linux/amd64
image: provectuslabs/kafka-ui:master
# image: provectuslabs/kafka-ui:latest
container_name: kafka-ui
restart: always
env_file:
- .env
environment:
DYNAMIC_CONFIG_ENABLED: true
KAFKA_CLUSTERS_0_NAME: kafka-cluster
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: broker:29092
KAFKA_CLUSTERS_0_METRICS_PORT: 9101
KAFKA_CLUSTERS_0_SCHEMAREGISTRY: http://schema-registry:8081
KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME: kafka-connect-cluster
KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS: http://kafka-connect:8083
KAFKA_CLUSTERS_0_KSQLDBSERVER: http://ksqldb-server:8088
ports:
- 8888:8080
volumes:
#- /tmp/config.yml:/etc/kafkaui/dynamic_config.yaml
- kafkaui_dir:/etc/kafkaui
networks:
- kafka-network
depends_on:
- broker
- schema-registry
- kafka-connect
- ksqldb-server
networks:
kafka-network:
driver: bridge
volumes:
broker_logdir:
kafkaui_dir:This file defines the services that will be used to run Kafka, Schema Registry, ksqlDB, and Kafka Connect. It also sets up the necessary volumes and networks.
Start the Container
Now that we have our environment file and Docker compose file set up, it's time to start the container! Run the following command:
docker-compose -f kafka-docker-compose.yml up -dThis will start all the containers/services in detached mode, meaning they will run in the background.
List Kafka Cluster
Once the containers are running, you can list the available Kafka clusters using the following command:
rest_proxy='http://127.0.0.1:8082'
curl -s -k -X GET ${rest_proxy}/v3/clusters | jqThis will display a list of all available Kafka clusters.
Get Kafka Cluster Id
cluster_id=`curl -s -k -X GET ${rest_proxy}/v3/clusters | jq -r '.data | .[0].cluster_id'`Create Kafka Topics
Now let us create two Kafka Topics namely pageviews & users-
curl -s -k -X POST -H "Content-Type: application/json" ${rest_proxy}/v3/clusters/${cluster_id}/topics \
--data '{"topic_name": "pageviews", "partitions_count": 1, "replication_factor": 1, "configs": [{"name": "cleanup.policy", "value": "delete"},{"name": "retention.ms", "value": 3600000}]}' | jq
curl -s -k -X POST -H "Content-Type: application/json" ${rest_proxy}/v3/clusters/${cluster_id}/topics \
--data '{"topic_name": "users", "partitions_count": 1, "replication_factor": 1, "configs": [{"name": "cleanup.policy", "value": "delete"},{"name": "retention.ms", "value": 3600000}]}' | jqList Kafka Topics
curl -s -k -X GET ${rest_proxy}/v3/clusters/${cluster_id}/topics | jq | grep '.topic_name'List Kafka Connector Plugins
kafka_connect='http://127.0.0.1:8083'
curl -s -k -X GET ${kafka_connect}/connector-plugins | jqCreate Kafka Connectors
We will generate mock data using Datagen Source Connector.
datagen-pageviews.json
{
"name": "datagen-pageviews",
"connector.class": "io.confluent.kafka.connect.datagen.DatagenConnector",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"kafka.topic": "pageviews",
"quickstart": "pageviews",
"max.interval": 10000,
"tasks.max": "1"
}datagen-users.json
{
"name": "datagen-users",
"connector.class": "io.confluent.kafka.connect.datagen.DatagenConnector",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"kafka.topic": "users",
"quickstart": "users",
"max.interval": 10000,
"tasks.max": "1"
}file='datagen-pageviews.json'
cname='datagen-pageviews'
curl -k -s -X PUT -H "Content-Type: application/json" -d @${file} ${kafka_connect}/connectors/${cname}/config | jq .
file='datagen-users.json'
cname='datagen-users'
curl -k -s -X PUT -H "Content-Type: application/json" -d @${file} ${kafka_connect}/connectors/${cname}/config | jq .Also let us add a S3 Sink Connector.
tgt-s3-sink-insert-user.json
{
"aws.access.key.id": "XXXXXXXXXXXXX",
"aws.secret.access.key": "XXXXXXXXXXXXXXX",
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"flush.size": "300",
"format.class": "io.confluent.connect.s3.format.json.JsonFormat",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": "false",
"name": "tgt-s3-sink-insert-user",
"rotate.schedule.interval.ms": "60000",
"s3.bucket.name": "kafka-s3-tgt",
"s3.region": "ap-southeast-1",
"storage.class": "io.confluent.connect.s3.storage.S3Storage",
"tasks.max": "1",
"timezone": "UTC",
"topics": "users",
"topics.dir": "kafka"
}file='tgt-s3-sink-insert-user.json'
cname='tgt-s3-sink-insert-user'
curl -k -s -X PUT -H "Content-Type: application/json" -d @${file} ${kafka_connect}/connectors/${cname}/config | jq .List Kafka Connectors
curl -s -k -X GET ${kafka_connect}/connectors | jqList Schemas in Schema Registry
schema_registry='http://127.0.0.1:8081'
curl -s -k -X GET ${schema_registry}/schemas | jq
curl -s -k -X GET ${schema_registry}/subjects | jqKafka-UI
Now let's visit the Kafka User Interface at http://127.0.0.1:8888 from browser.
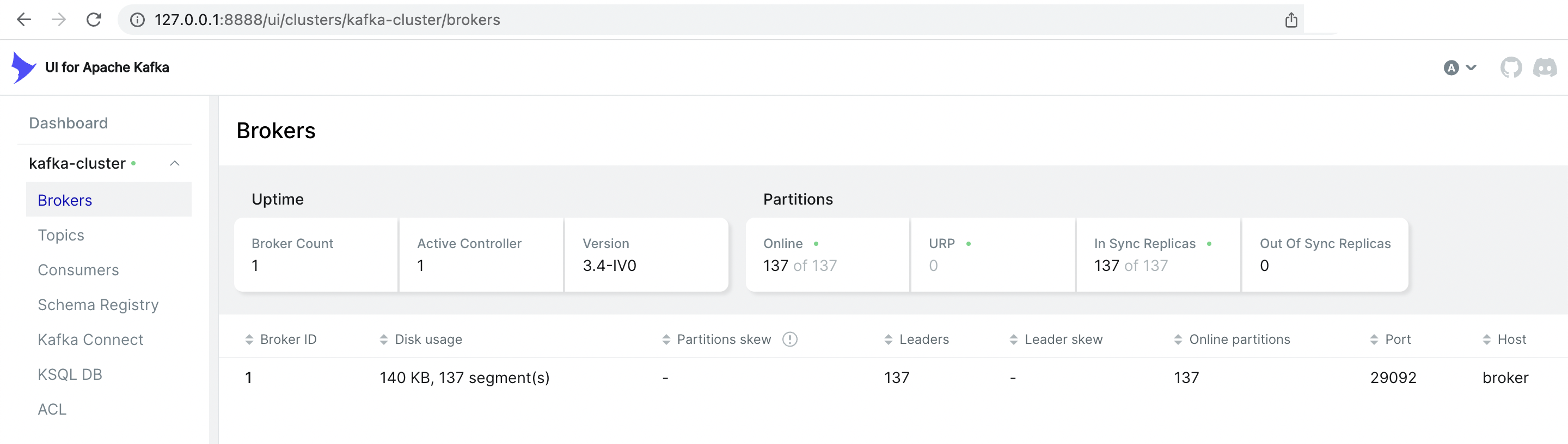
Create ksqlDB stream and table
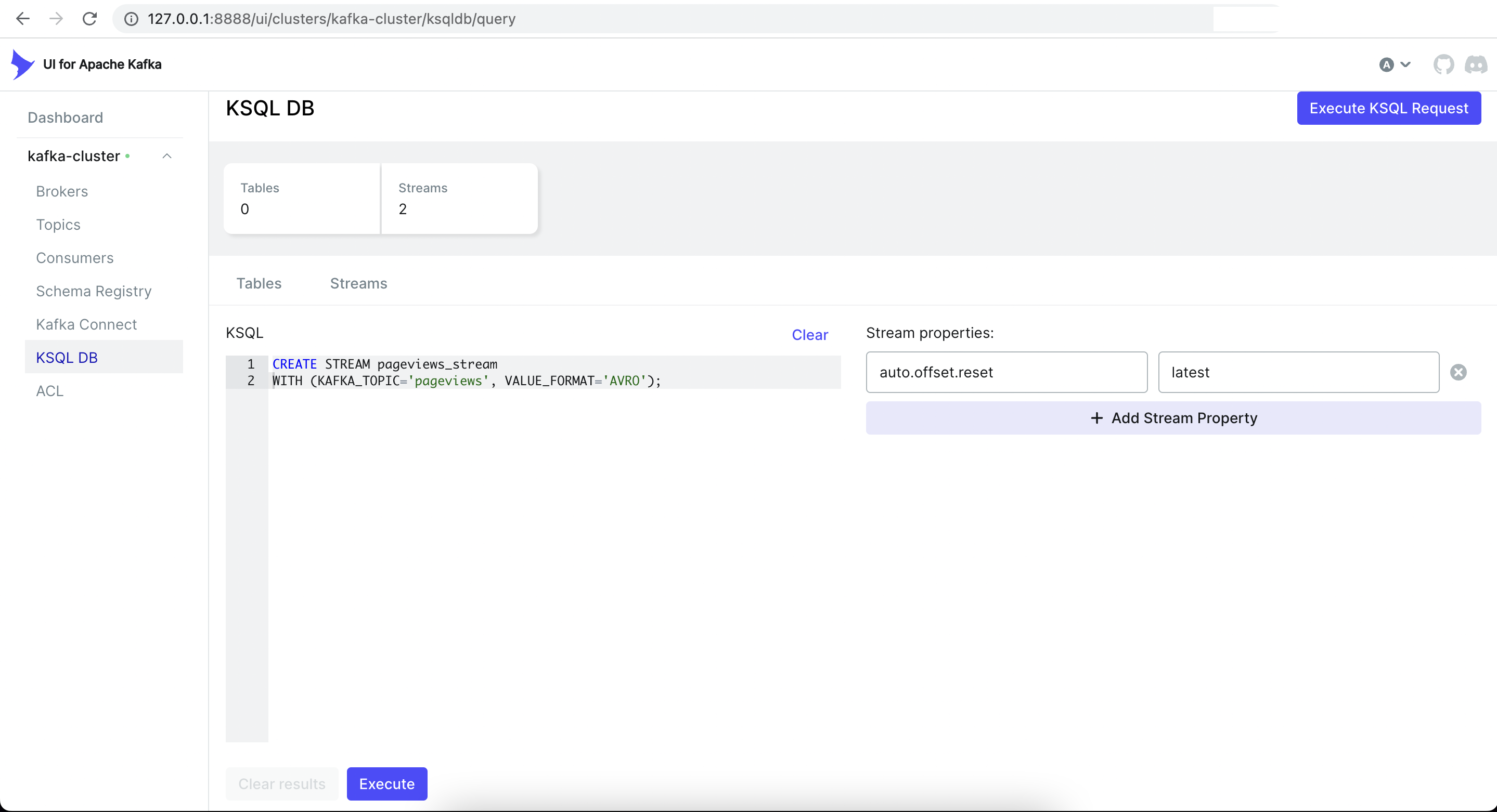
Now we will create a stream & a table from the UI.
CREATE STREAM pageviews_stream
WITH (KAFKA_TOPIC='pageviews', VALUE_FORMAT='AVRO');This will create a new stream named pageviews_stream that reads data from the pageviews topic.
Use the below command to display the contents of the stream.
SELECT * FROM pageviews_stream EMIT CHANGES;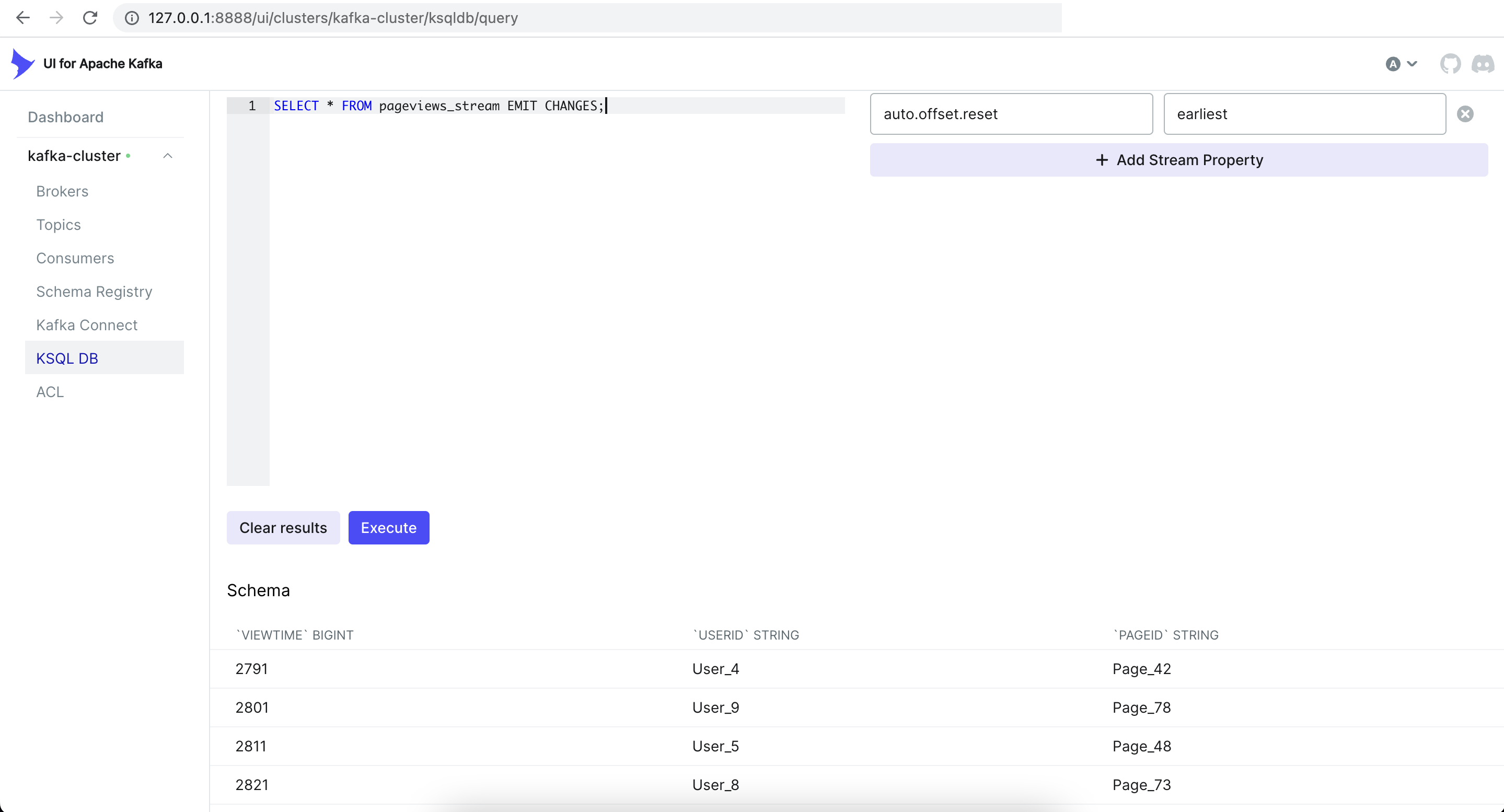
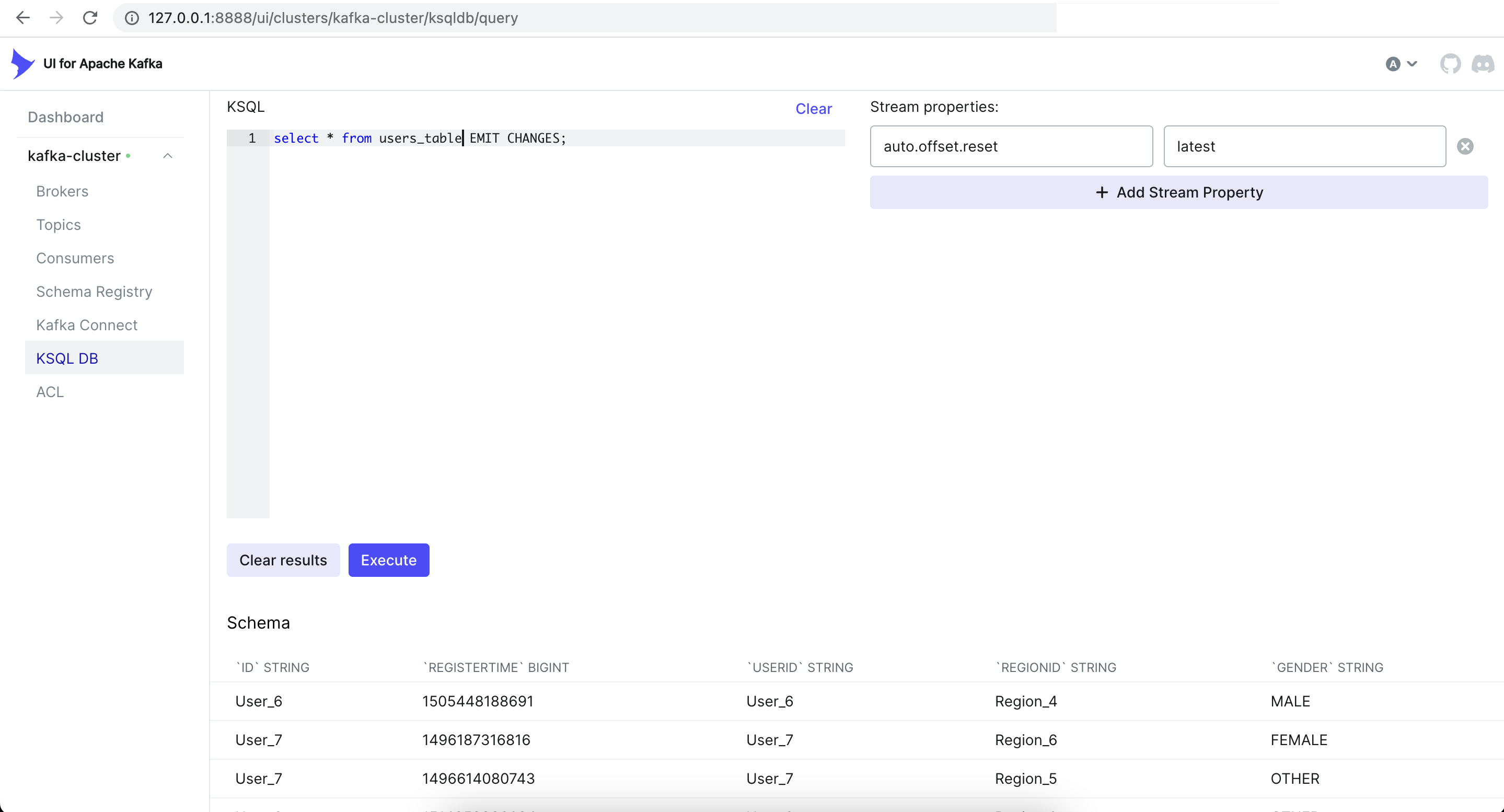
To create a table, we can use the following command:
CREATE TABLE users_table (id VARCHAR PRIMARY KEY)
WITH (KAFKA_TOPIC='users', VALUE_FORMAT='AVRO');This will create a new table named users_table that reads data from the users topic.
Joining Streams and Tables
To join two streams or tables, you can use the following command:
CREATE STREAM user_pageviews
AS SELECT users_table.id AS userid, pageid, regionid, gender
FROM pageviews_stream
LEFT JOIN users_table ON pageviews_stream.userid = users_table.id
EMIT CHANGES;This will create a new stream named user_pageviews that joins the pageviews_stream and users_table.
select * from user_pageviews EMIT CHANGES;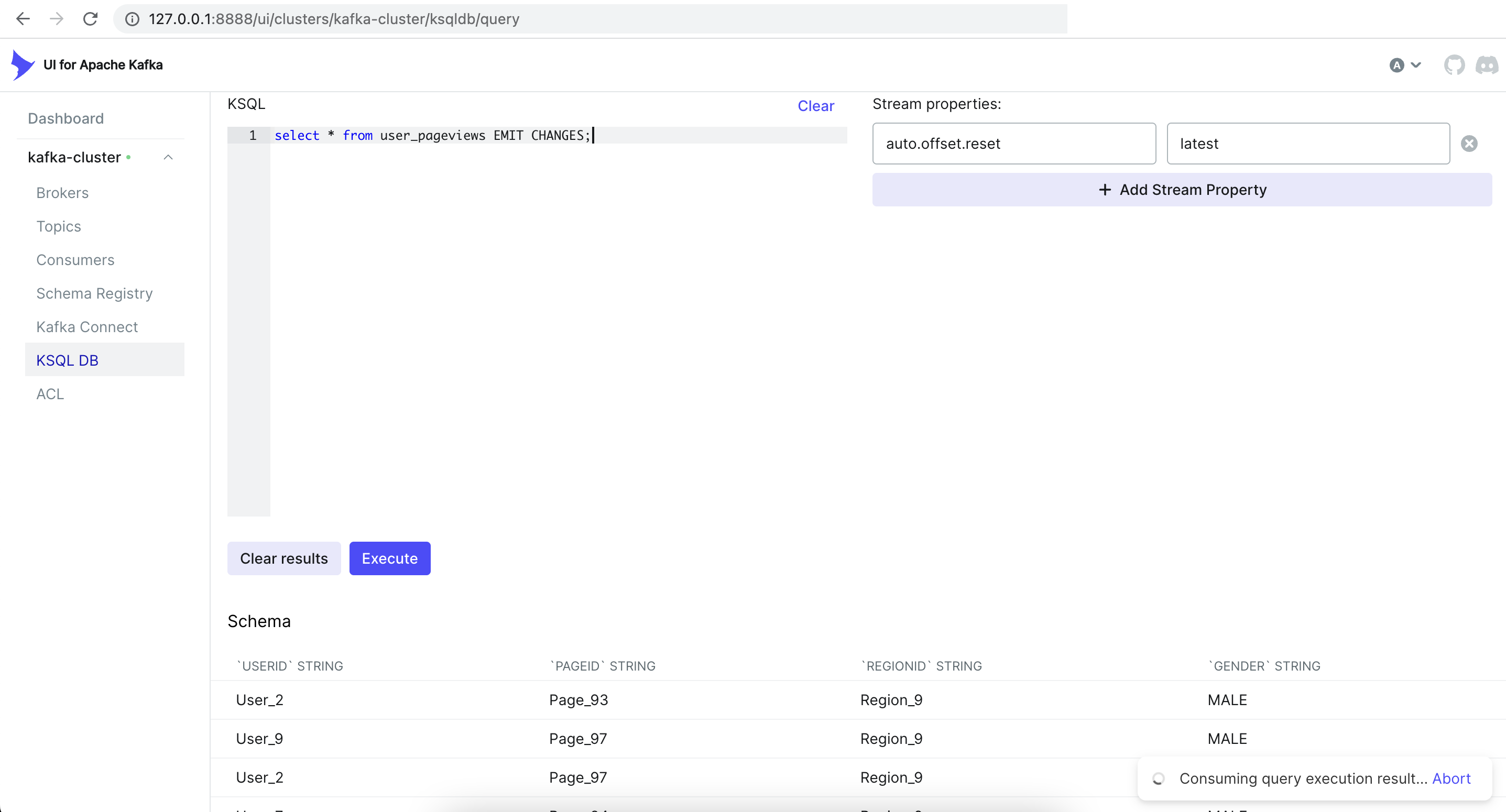
Stop the Container
Finally, we can stop the containers by running the following command:
docker-compose -f kafka-docker-compose.yml downThis will stop the containers and remove them from memory.
NOTE:
For MacOS M1, confluent have also released the images based on arm architecture.
https://hub.docker.com/u/confluentinc
- confluentinc/cp-kafka:7.5.1.arm64
- confluentinc/cp-schema-registry:7.5.1.arm64
- confluentinc/cp-kafka-rest:7.5.1.arm64
- confluentinc/cp-kafka-connect:7.5.1.arm64
- confluentinc/cp-ksqldb-server:7.5.1.arm64
In this article, we have covered how to set up a Kafka cluster using Docker, create topics and connectors, and use ksqlDB to process data. We have also demonstrated how to join streams and tables using ksqlDB.
